hadoop hdfs吞吐量SEARCH AGGREGATION


問題描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:Hadoop是目前被廣泛使用的大數據平臺,Hadoop平臺主要有Hadoop Common、HDFS、Hadoop Yarn、Hadoop MapReduce和Hadoop Ozone。Hadoop平臺目前被行業使用多年,有健全的生態和大量的應用案例,同時Hadoop對硬件的要求比較低,非常適合初學者自學。目前很多商用大數據平臺也是基于Hadoop構建的,所以Hadoop是大數據開發的一個重要內容...
 wizChen
|
1275人閱讀
wizChen
|
1275人閱讀
回答:Hadoop生態Apache?Hadoop?項目開發了用于可靠,可擴展的分布式計算的開源軟件。Apache Hadoop軟件庫是一個框架,該框架允許使用簡單的編程模型跨計算機集群對大型數據集進行分布式處理。 它旨在從單個服務器擴展到數千臺機器,每臺機器都提供本地計算和存儲。 庫本身不是設計用來依靠硬件來提供高可用性,而是設計為在應用程序層檢測和處理故障,因此可以在計算機集群的頂部提供高可用性服務,...
 娣辯孩
|
1490人閱讀
娣辯孩
|
1490人閱讀
回答:1998年9月4日,Google公司在美國硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。無獨有偶,一位名叫Doug?Cutting的美國工程師,也迷上了搜索引擎。他做了一個用于文本搜索的函數庫(姑且理解為軟件的功能組件),命名為Lucene。左為Doug Cutting,右為Lucene的LOGOLucene是用JAVA寫成的,目標是為各種中小型應用軟件加入全文檢索功能。因為好用而且開源(...
 ctriptech
|
849人閱讀
ctriptech
|
849人閱讀

...容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。HDFS可以實現流的形式訪問(streaming access)文件系統中的數據。 它是基于流數據模式的訪問和處理超大文件。(分布式...
...e基于列的而不是基于行的模式。 Kafka角色:Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能...
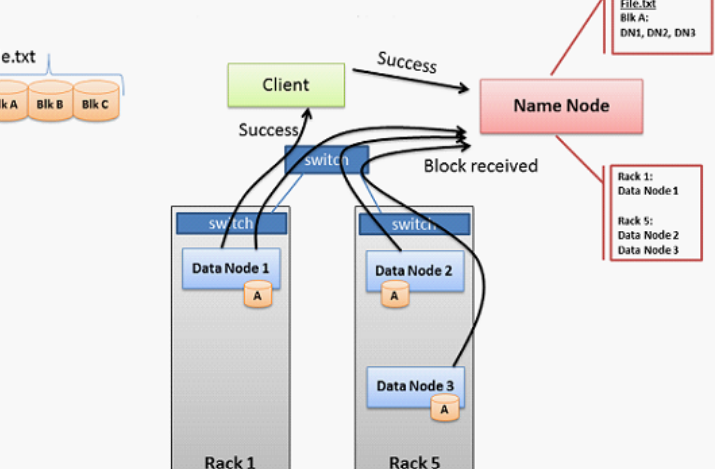
...件上 HDFS適合批量處理,而不是用戶交互使用。重點是高吞吐量的數據訪問,而不是低延遲的數據訪問。 運行在HDFS上的應用程序具有較大的數據集。因此,HDFS被調優以支持大文件。 HDFS設計思想: 分而治之 負載均衡??HDFS...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...


 dmlllll
dmlllll 鄒立鵬
鄒立鵬









